
π0.7: Prompt Engineering Comes to Robot Foundation Models
π0.7’s key advance is full action context, not just a stronger model—unlocking compositional generalization.


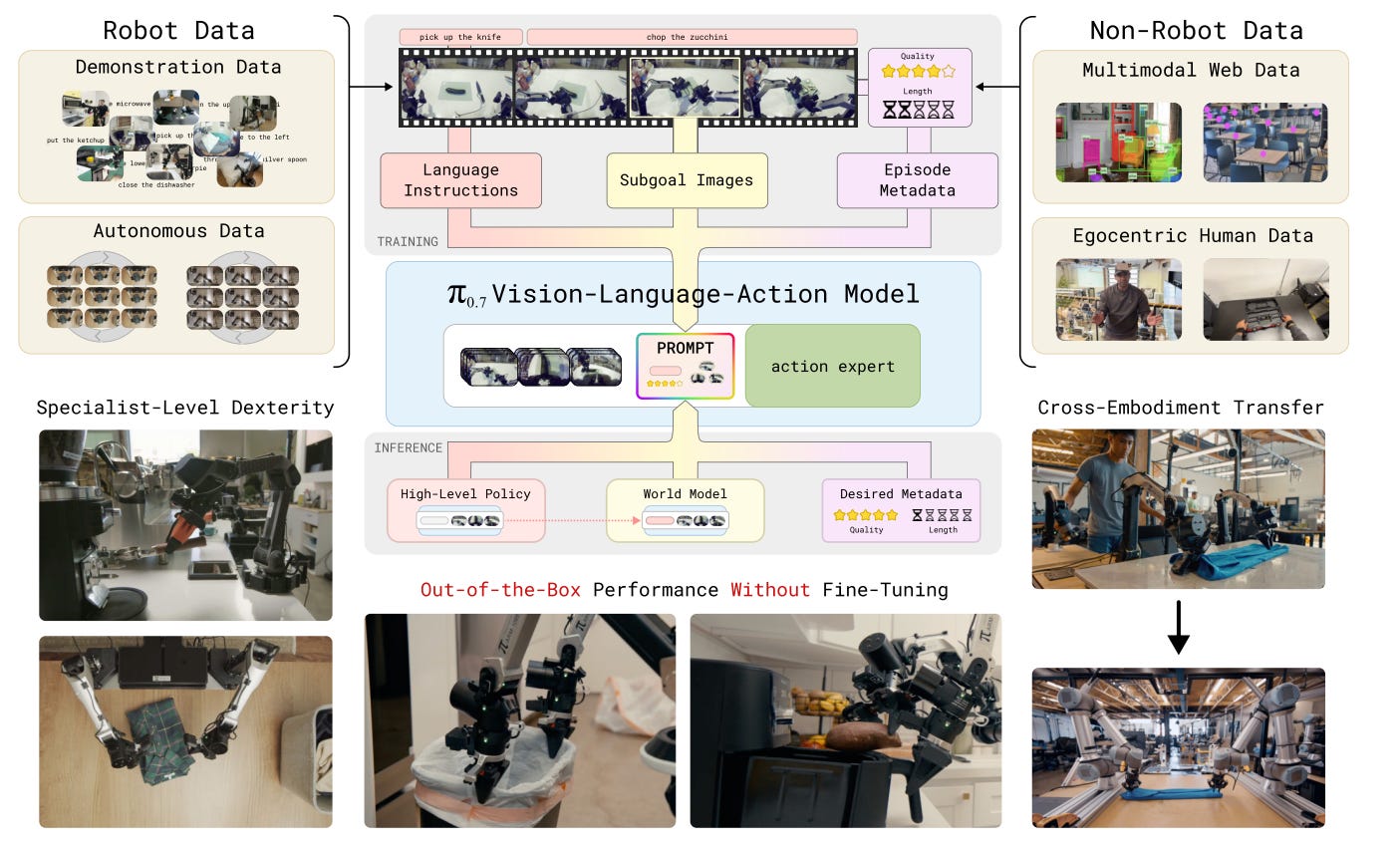
π0.7 expands the input to a robot policy from a single task instruction into a full context for how to act: language subtasks, subgoal images, episode metadata, and control mode. That is why it starts to show something robot learning has long been missing: compositional generalization.
Overview
Physical Intelligence recently released π0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities.
https://www.pi.website/blog/pi07
https://arxiv.org/pdf/2604.15483
My main takeaway is simple:
The key step in π0.7 is not just better performance. It is that the model no longer takes only a task instruction. It takes a full prompt about how to do the task. That includes language subtasks, subgoal images, episode metadata, and control mode. Because of that, it starts to show clear signs of compositional generalization.
What matters most in this paper is not one flashy demo.
What matters is the broader recipe: absorb all usable data, then use richer prompts and context to explicitly tell the model about strategy differences, quality differences, and goal differences inside that data.
That way, the model learns not only what to do, but also:
how to do it
how fast to do it
how well to do it
whether mistakes happened
Why this matters
1. Robot prompt engineering becomes a core paradigm
Many robot VLAs still use a very simple prompt. In practice, it is often just a task description.
π0.7 goes much further. Its prompt can include:
task and subtask language
subgoal images
episode metadata such as speed, quality, and mistakes
control mode such as joint control or end-effector control
This matters because robot data is naturally messy.
Even for the same task, one operator may be fast, another careful. Some trajectories are expert demonstrations. Some are failed trajectories. Some are autonomous rollouts.
Without extra context, all of these modes get mixed together. Then the model tends to learn an average behavior that looks like nobody.
That is the core idea of π0.7:
Use prompting to explicitly separate these modes.
My own read is that π0.7 is fundamentally a diverse prompting strategy for robot models. It feels similar to prompt expansion in language models and video models.
The contribution is not just scaling parameters. It is organizing the conditioning signal in a much richer and more controllable way.
2. Mixed-quality data is not just usable. It may be the better route.
One strong signal from this paper is that low-quality data, failed data, autonomous rollout data, and even non-robot data do not have to be treated as noise.
If the conditioning is done correctly, they can become useful training signals.
The ablations are especially important here. Without metadata, model performance can drop as the dataset gets larger but lower-quality on average. With metadata, π0.7 keeps improving as more mixed-quality data is added.
That is a very important result.
It suggests that the key problem in future robot learning is not simply filtering data harder. It is:
How do we organize messy but real-world data so that the model can actually learn from it?
3. Compositional generalization finally starts to look real
One major weakness of current robot foundation models is that semantic generalization is often better than compositional generalization.
A model may recognize many objects and many task words. But once you change the tool, change the order, or recombine skills in a new way, performance often collapses.
π0.7 is interesting because it starts to show several more convincing forms of compositional behavior:
it can perform some new short-horizon tasks out of the box
it can handle new long-horizon tasks through step-by-step human coaching
it can distill those coaching trajectories into a higher-level language policy for autonomous execution
That is much closer to how humans teach real skills.
We do not always collect thousands of low-level action labels first. Sometimes we explain the task step by step, then refine it into a repeatable skill.
The most impressive results
1. One generalist model can match specialists
One of the strongest results in the paper is that π0.7 can match, and in some cases exceed, task-specific specialist policies on several dexterous tasks.
Examples include:
espresso making
box building
laundry folding
This is important because the usual assumption is:
generalist model = broader, but weaker
specialist model = stronger, but narrower
π0.7 pushes back on that tradeoff.
It suggests that with the right data recipe and the right prompting strategy, a generalist model can absorb specialist capability without giving up much performance.
2. It is actually listening to language, not just replaying dataset bias
The paper includes a very nice test called Reverse Bussing.
In the training data, the normal pattern is:
trash goes into the trash
dishes go into the bussing bin
At test time, the instruction is reversed:
trash goes into the bussing bin
dishes go into the trash
There is also Reverse Fridge to Microwave, which similarly goes against the dominant direction in the dataset.
π0.7 performs much better than earlier models on these tasks.
That matters a lot.
Many robot models seem to follow language until language conflicts with the strongest bias in the training data. Then they fall back to the common pattern.
π0.7 is still not perfect, but at least it shows that language is no longer just decoration. It is starting to genuinely steer behavior.
3. Cross-embodiment transfer starts to look real
The paper also has a very interesting embodiment transfer result.
They collect shirt-folding and laundry-folding data on a smaller bimanual robot, then transfer the skill zero-shot to a much larger dual-UR5e platform.
What is interesting is that the new robot does not simply replay the same motion pattern.
Instead, it finds a different strategy that better fits its own geometry and dynamics. For example, the smaller robot may pick up clothes from the side, while the larger UR5e setup prefers a more top-down vertical grasp.
Even more striking, the zero-shot transferred policy gets very close to expert teleoperators on shirt folding.
That suggests the model is not just imitating source trajectories. It is learning something more like a higher-level manipulation skill.
Important details
1. The point is not just a bigger model
A key detail here is that π0.7 is not simply a giant video diffusion robot policy.
The main VLA is around 5B:
a Gemma3 4B VLM backbone
a MEM-style video history encoder
an 860M flow-matching action expert
It also continues PI’s earlier ingredients:
knowledge insulation
FAST tokens
flow matching objectives
The larger branch is the one used to generate subgoal images. That branch is initialized from BAGEL 14B and is responsible for turning language subtasks into near-future multi-view goal images.
So the important point is not “just make the model bigger.”
The important point is:
Build a system with clear division of labor, then connect language, world goals, actions, and data quality through prompting.
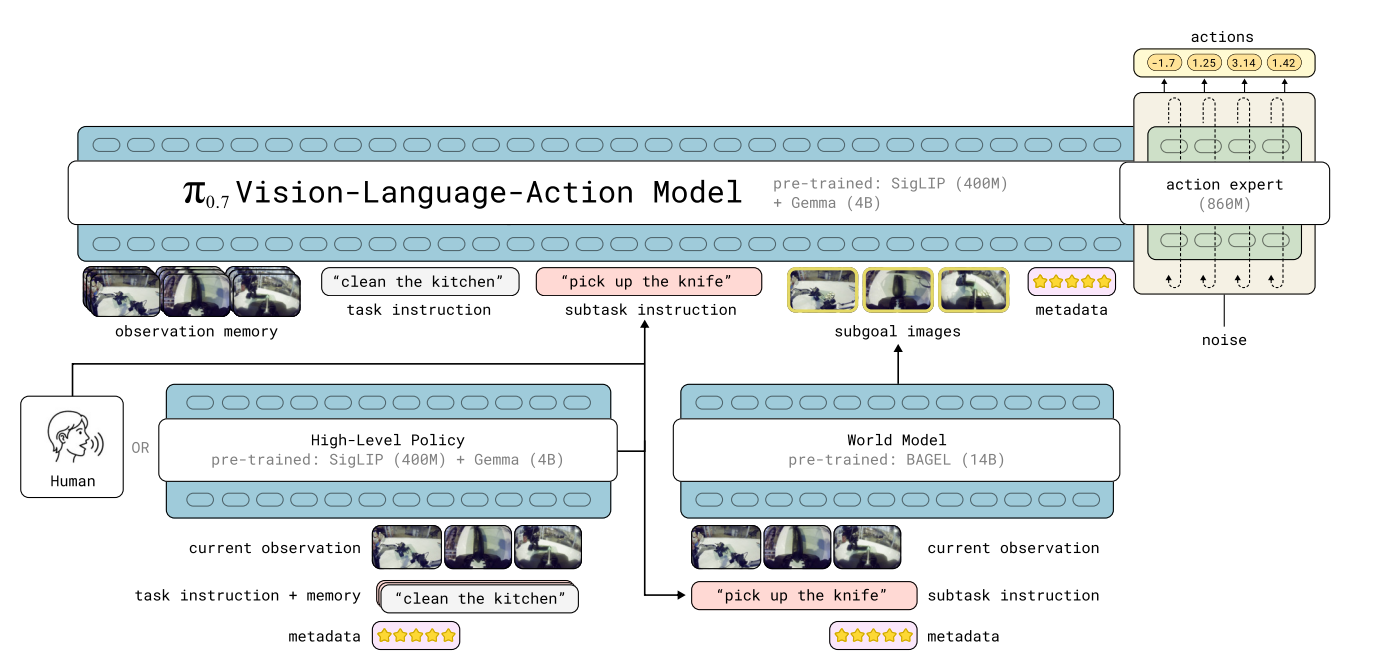
2. Subgoal images are genuinely useful
Goal conditioning is not new. But π0.7 uses it in a much more systematic way.
It does not rely on a single goal image. It uses multi-view subgoals, including base views and wrist views.
That is important because the goal needs to specify both:
what should happen to the object and the scene
what state the robot arms and grippers should reach
The paper also makes two practical engineering choices I like:
randomly dropping different parts of the prompt during training
mixing real future images with generated goal images during training
Both are very pragmatic.
The first makes the model robust to different prompt subsets at test time.
The second reduces the mismatch between training and deployment, since test-time subgoals may come from the world model rather than from ground-truth future frames.
3. The ablation story is unusually strong
I also like the ablations in this paper.
They are not just “remove one module and report the drop.” They ask more basic questions:
Can the model really learn from mixed-quality data?
Does data diversity actually improve generalization?
One especially good experiment compares:
removing the most diverse 20% of the data
removing a random 20%
The result is very clear: removing the most diverse 20% hurts much more.
That means the important variable is not only data scale. It is task diversity.
My take
1. Using all data sources, especially egocentric human data, is the 2026 direction
My view is pretty clear here.
Demonstrations, suboptimal data, autonomous rollouts, egocentric human video, and web multimodal data should all move into the same training pipeline.
The key question is no longer whether to mix them.
The key question is how to condition on them correctly.
2. “Dexterous task” is still a bit hand-wavy
I increasingly think dexterity should be split into at least two levels:
wrist dexterity: folding laundry, peeling vegetables, handling objects with richer contact
finger dexterity: pressing small buttons, using a mouse, fine in-hand manipulation, true multi-finger regrasp
π0.7 looks very strong on the first category.
It still looks much less convincing on the second.
That boundary matters, and I think many robotics papers still blur it too much.
3. “Embodiment” is also becoming hand-wavy
For UMI-style or end-effector-centric approaches, embodiment often mainly means the end-effector interface.
As long as the hand pose trajectory is aligned, the arm and body can often be abstracted away and handled by IK or other lower-level controllers.
But for PI-style joint-level policies, the robot arm itself is part of the embodiment.
That is because the model directly predicts joint-level control. It must understand how this specific robot moves in order to choose a good strategy.
The laundry-folding transfer result shows this nicely. A smaller arm and a larger UR5e do not just execute the same motion with different scales. They may prefer different grasping strategies altogether.
My own view is that if UMI-like approaches are going to scale well, the robot body may need to become more human-like, at least in upper-body geometry and reachable manipulation space. That would make human hand 6D motion easier to reproduce with lower-level controllers.
4. Goal conditioning is powerful, but I still have doubts about long-term scalability
To be honest, I think the goal-conditioned route is very effective, but also somewhat hacky.
It makes the learning problem easier. But it also separates the system into two parts:
one module generates the goal or subgoal
another module executes the trajectory conditioned on that goal
This is practical, and clearly useful.
But it can also introduce suboptimality. If the generated goal is not quite right, the downstream policy may still be pulled in the wrong direction.
So my current view is:
This is a strong near-term direction. I am just not yet convinced it is the final scalable form of a unified robot foundation model.
My open question
The biggest open question for me is this:
How well can π0.7-style generalization transfer from grippers and parallel-jaw grippers to truly dexterous hands?
I am still skeptical.
The gap from grippers to dexterous hands may be much larger than the arm-morphology gap shown in this paper.
It is not just about reach, inertia, or kinematics.
The action space changes. The contact modes change. The manipulation regime changes.
If that gap turns out to be too large, then many current “cross-embodiment” conclusions may still mostly hold inside the gripper world.
Final take
If I had to summarize π0.7 in one sentence, I would say this:
It is one of the clearest demonstrations so far that the next step in robot foundation models is not just larger models, and not just cleaner data, but richer prompts, messier but more realistic data, and stronger steerability.
What excites me most is not one benchmark result.
It is that π0.7 pushes robot learning away from the old interface of “collect trajectories and train a policy,” and toward a new interface of prompt, coach, steer, and compose.
That feels much closer to the path toward truly general robot models.