
NVIDIA EgoScale: Pretraining Dexterous Manipulation with 20,000 Hours of Egocentric Human Data
A simple but important idea: pretrain on large-scale human egocentric data first, then use a small amount of aligned human–robot data and robot demonstrations to make it work on real dexterous hands.


Overview
Recently NVIDIA GEAR released EgoScale. My one-line summary is:
Use egocentric human video plus wrist and hand motion as a scalable supervision signal to pretrain a VLA. Then use a small amount of aligned human–robot data plus robot data to make it work on real dexterous manipulation.
That is the core recipe.
The most important point is that this paper does not just show transfer. It shows a scaling law. EgoScale pretrains on 20,854 hours of egocentric human video. In the scaling study, average downstream task completion rises from 0.30 at 1k hours to 0.71 at 20k hours. The human-action validation loss follows a near log-linear trend, and that offline loss tracks real robot performance closely.
So my main takeaway is simple:
This paper argues that dexterous manipulation can be pretrained from large-scale human data first, then aligned and improved with a much smaller amount of robot data.
Why this matters
1. It systematically shows that human data can scale for dexterous manipulation
Earlier human-to-robot work already showed that transfer is possible. EgoScale is the scale-up version. The paper explicitly argues that prior work was limited by smaller human datasets and by lower-DoF hands. EgoScale pushes pretraining to more than 20,854 hours, which is over 20× larger than prior efforts, and it tests transfer on a 22-DoF dexterous hand rather than a simple gripper.
So the bigger question here is:
Can dexterous manipulation be pretrained from large-scale human data?
EgoScale’s answer is yes. That is why I think this paper matters. It suggests that dexterous foundation models may move from a robot-data-first route to a human-data-first route.
This is also why I see EgoScale as a natural extension of work like EgoMimic, EgoVLA, DexWild, and related human-to-robot transfer papers. The difference is not only better engineering. The difference is scale.
2. It shows a strong link from offline metric to real robot performance
This is the part I care about most. The paper shows that human-action validation loss is not just an offline number. It correlates strongly with downstream real-robot task completion. That makes pretraining much more predictable. If the validation loss keeps improving at scale, downstream robot performance is likely to improve too.
That is a big deal. In many robot papers, offline metrics and real-world performance are only loosely connected. Here the paper is saying something stronger: the offline pretraining metric is actually useful.
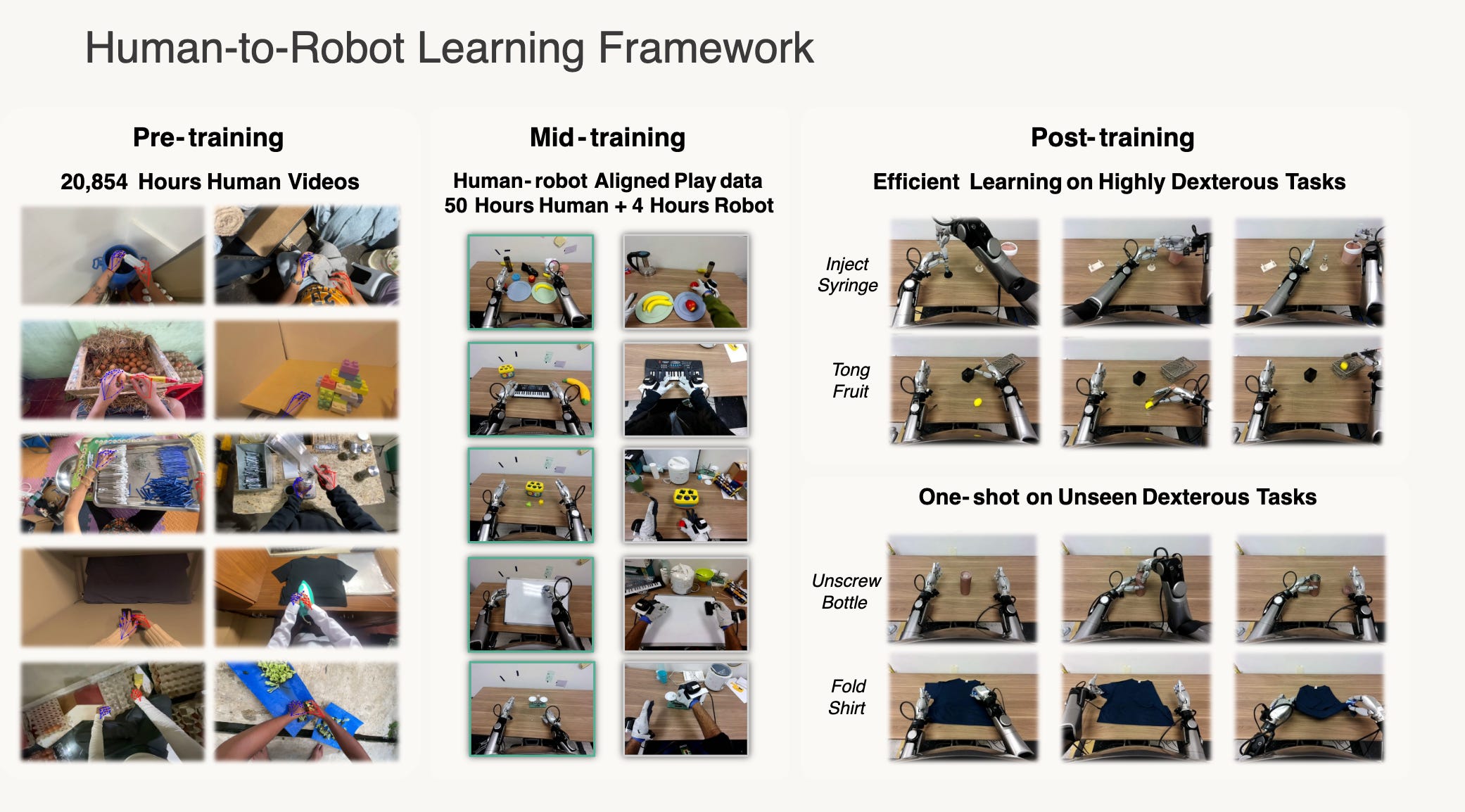
Important details
1. Action representation
The paper makes a very clear action-representation choice.
For the arm / wrist: use relative wrist motion between consecutive timesteps. This avoids relying on a fixed global coordinate frame.
For the fingers: retarget human hand motion into a 22-DoF dexterous hand joint space.
Why this matters: the wrist-only version performs badly. The fingertip-based version is better, but still inconsistent. The retargeted joint-space hand action is the most stable choice across tasks.
My read is simple:
Wrist motion + finger motion is becoming the main representation.
The robot’s native joint format matters less.
The most transferable interface is how the wrist moves and how the fingers move.
That is not the paper’s exact wording. But it is the clearest design message I take from it.
2. The data pyramid
The training recipe is the paper.
Stage I: very large human pretraining.
The model is pretrained on 20,854 hours of egocentric human data. The main corpus spans 9,869 scenes, 6,015 tasks, and 43,237 objects. Most of it is in-the-wild first-person video. The supervision is noisy but scalable. The mixture is also complemented by 829 hours of EgoDex with more accurate wrist and hand tracking.Stage II: small aligned human–robot mid-training.
This dataset contains 344 tabletop tasks. Each task has about 30 human trajectories and 5 robot trajectories, totaling about 50 hours of human data and 4 hours of robot data. The setup is carefully aligned: matched viewpoints, calibrated intrinsics, Vive trackers for wrist pose, and Manus gloves for in-hand motion.Stage III: task post-training.
The policy is then fine-tuned on five dexterous tasks on the Galaxea R1 Pro. Most tasks use 100 teleoperated robot demonstrations. Shirt rolling uses 20. The five tasks are shirt rolling, card sorting, tong-based fruit transfer, bottle-cap unscrewing, and syringe liquid transfer.
My own read of this recipe is:
Pretraining is mainly for learning broad manipulation priors: real-world dynamics, semantic grounding, robustness, and scene generalization.
Mid-training is for alignment. It grounds the pretrained representation in the robot’s sensing and control space.
Post-training is for task performance. It turns the prior into reliable task completion.
So I do not read EgoScale as “robot data is no longer needed.” The paper’s recipe is more precise than that:
Use huge, cheap human data for scale.
Use small aligned data for grounding.
Use a limited amount of robot task data for success rate.
There is another important implication here. For Stage I, the paper suggests that scale and diversity matter more than perfect precision. The data is noisy and not sensor-aligned, but it still beats the small aligned-only baseline across most tasks. That is a very foundation-model-like result.
3. One-shot adaptation is a strong result
The paper also evaluates adaptation to unseen skills under very limited robot supervision.
Start from the human-pretrained model.
Do aligned mid-training.
Post-train on a new task with only 1 robot demonstration plus 100 aligned human demonstrations.
In that setting, the model reaches 0.88 success on fold-shirt and 0.55 success on unscrewing water bottles. Models that remove either large-scale human pretraining or aligned mid-training fail in this setting. This is a strong sign that the pretrained representation is doing real work.
4. Wrist camera is very important
This is another point I strongly agree with.
The robot uses three RGB cameras:
one head-mounted egocentric camera
two wrist cameras facing the palm
This is not elegant. But it is practical. For dexterous tasks, the wrist view is extremely useful. It sees contact details that the head camera often misses. That matters for cards, tongs, bottle caps, and syringe operations, where small contact errors cause the whole task to fail.
There is also an interesting gap here. The large-scale Stage I human pretraining is mostly ordinary egocentric video, while the robot and aligned mid-training setup use the richer head-plus-wrist camera configuration. So one obvious question is:
If we also add wrist-view human data at scale, would transfer improve further?
Cross-embodiment transfer
The paper also tests transfer to a different embodiment: the Unitree G1 with a 7-DoF tri-finger hand.
The G1 has a shorter arm and different kinematics.
The tasks are Pen in Bin and Dish in Rack.
Human pretraining plus embodiment-specific mid-training improves performance substantially over using the G1 data alone.
The paper’s intended message is clear: large-scale human motion learns a reusable motor prior. It is not completely tied to one dexterous hand. I think that claim is directionally right. But my own view is still narrower: this kind of pretraining should work best when the downstream robot also has reasonably dexterous hands. Human data transfers most naturally when the robot can express similar finger behaviors.
My 2026 take
My takeaway is straightforward.
Very low-cost human video will become a major pretraining source for embodied models.
Dexterous hands will become the most important end effector for transferring human manipulation data well.
Finger actions and wrist 6D motion will become the key representation layer.
The main bottleneck will move to collecting high-quality robot data cheaply for alignment and post-training.
EgoScale does not prove every one of those points by itself. But it strongly points in that direction. The paper already shows that large, noisy human data can supply strong priors, that aligned mid-training makes those priors executable, and that small amounts of robot data then go much farther than they would from scratch.
This is why I see EgoScale as a paradigm-shift paper. The pretraining data can be low precision, cheap, and massive. The later-stage data can be smaller, more expensive, and more precise. That looks much closer to the foundation-model playbook than to the old robot imitation-learning playbook.
My questions
I still have a few open questions.
What if large-scale pretraining also includes wrist cameras?
The current Stage I data is mostly ordinary first-person video, while the robot setup depends heavily on wrist views. A human data collection pipeline that includes wrist-view video might reduce this perceptual gap.Can the mid-training stage be made much lighter?
Right now it still requires matched viewpoints, Vive trackers, and Manus gloves, with humans acting in a robot-compatible workspace. That is much heavier than the Stage I recipe. It clearly works, but it still looks expensive and unnatural for large-scale collection.If high-quality robot trajectory collection becomes cheap, do we still need mid-training?
Today, the paper shows that mid-training is very useful. It is what enables one-shot transfer in combination with human pretraining. But if robot data collection becomes dramatically cheaper and higher quality, it is worth asking whether some of the alignment role of mid-training could be replaced by more robot data directly.
A related technical question is whether better scalable data systems could improve Stage II and Stage III at the same time. The paper already shows that alignment data and teleoperated robot data matter. So the next bottleneck may simply be building a cheaper and higher-quality way to collect them.
Final take
I think the main message of EgoScale is very simple.
Dexterous manipulation may be moving from “robot data first” to “human data first.”
The “ego” in EgoScale is not just the camera viewpoint. It is the scalable supervision source. Use egocentric human video to pretrain broad motor priors. Use a small amount of aligned data to connect that prior to the robot. Then use a limited amount of robot data to drive task success.
That is the recipe. And this paper shows that the recipe actually scales.