
Robot Learning Should Be Goal-Driven and Data-First
A goal-driven view on robot learning, industrial deployment, and the data engine needed to scale dexterous robots.

Generalist AI recently published a blog that sparked a lot of discussion in robotics. The main takeaway is simple: robotics research should be more goal-driven than idea-driven.
Instead of starting from a method label — world model, VLA, end-to-end policy, diffusion policy — we should start from the actual objective and constraints.
What are we trying to achieve? What are the constraints today? Given those constraints, what is the most practical path forward?
This sounds more modest than chasing a single grand idea. But in robotics, I think this mindset is especially important.
The Waymo vs. Tesla analogy

This reminds me of the difference between Waymo and Tesla in autonomous driving.
Tesla has always been very good at explaining its technical vision publicly: BEVFormer perception, neural planning, end-to-end learning, world models, and so on. It is a very method-forward narrative.
Waymo feels more goal-driven. The goal is to launch truly driverless service safely and reliably. Given that objective, Waymo combines whatever methods are needed: sensors, maps, SOTA foundation models, simulation, safety validation, and large-scale operations.
The approaches may look less ideologically pure, but it is practical and effective, as Waymo continuously launches truly driverless robotaxi services in more and more cities. I think robot learning needs more of this attitude. The goal is not to prove that one model class is the final answer. The goal is to make robots work under real-world constraints.
What are the real constraints in robot learning?

For robot learning today, the biggest constraint is still data.
Compared with language models, robotics is still in a relatively low-data regime. We do not yet have anything close to internet-scale, high-quality robot interaction data.
Because of that, highly adaptive and generalized robot policies are still elusive. It is still hard to build one model that can reliably handle many tasks, many objects, and many environments.
This is why, at Chestnut Robotics, we focus first on industrial setups.
Industrial environments are not easy. But they are more structured and controlled than household environments. The workspace is more predictable. The object distribution is narrower. The success criteria are clearer. Given the current state of robot learning, this makes industrial manipulation a more practical place to start.
To me, this is a goal-driven choice. We are not trying to solve the hardest version of general-purpose robotics on day one. We are trying to choose a deployment setting where today’s models, hardware, and data pipelines can compound into real progress.
Tesla was right about data
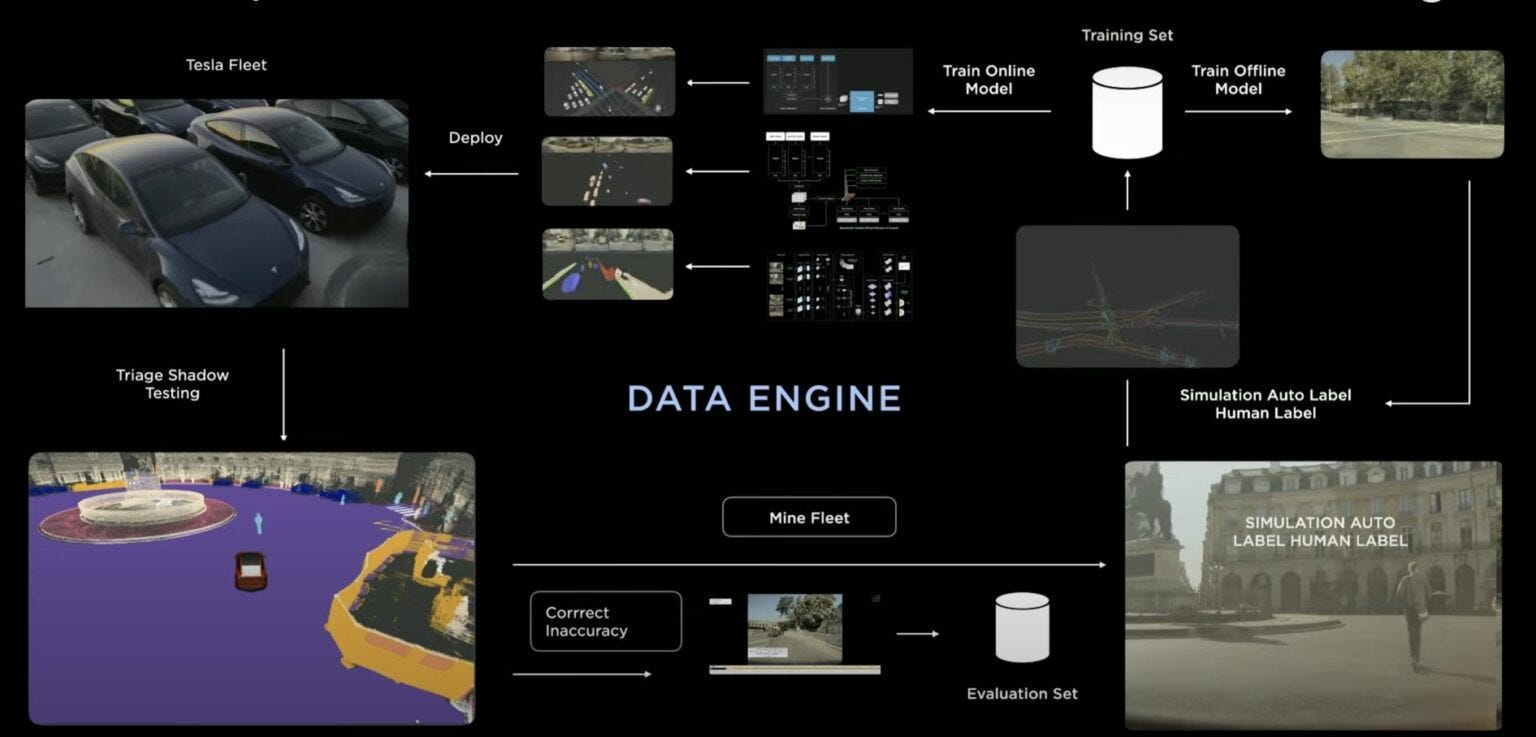
That said, Tesla also had a very important insight.
Even if one debates specific technical choices, Tesla understood early that autonomy would ultimately become a data-driven problem. Its product strategy allowed it to collect a huge amount of real-world driving data through deployed vehicles.
That data-first view is powerful. I think the same is true for robotics. The long-term winner in robot learning will not only have a better model. It will have a better data engine.
This is where robotics is harder than autonomous driving. High-quality robot data is expensive. Dexterous manipulation data is even more expensive. You need robots, operators, sensors, resets, maintenance, calibration, and a lot of trial and error. For robotic hands, the cost is even higher because contact-rich manipulation is fragile and high-dimensional.
So the key question becomes: How do we scale high-quality dexterous manipulation data?
Chestnut’s data strategy
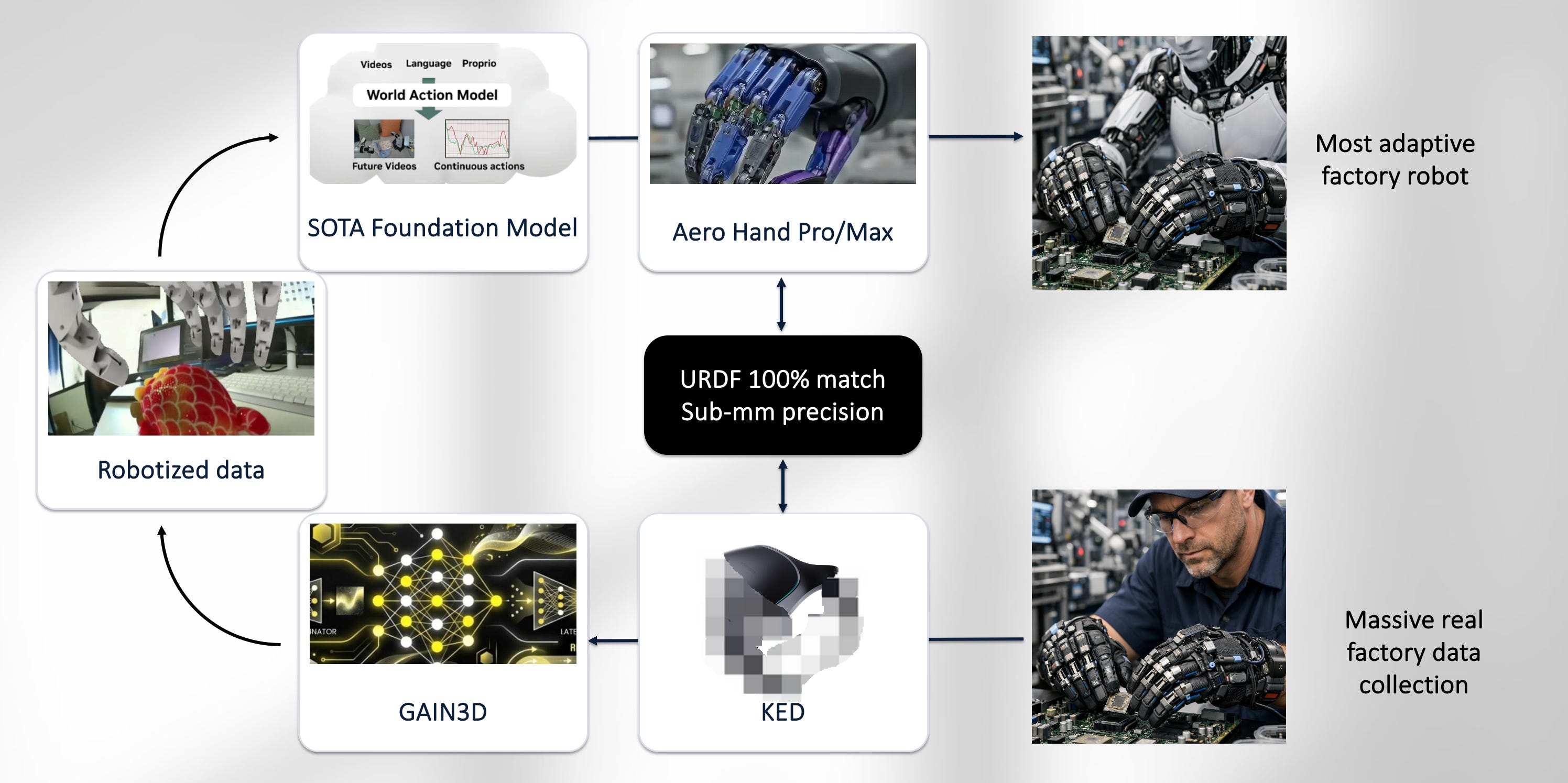
At Chestnut, our answer is to rethink the data collection pipeline. Instead of collecting all data directly through robot operation, we use a human-wearable exoskeleton to capture high-quality human dexterous manipulation data.
But the critical point is not just collecting human data. The critical point is conversion.
Through our co-designed robotic hand and generative inpainting algorithm, we can eventually convert human hand interaction data into high-quality robot data. This is the key merit of the system: we are not only recording humans; we are building a scalable bridge from human dexterity to robot dexterity.
This matters because human dexterous data is much easier to scale than robot dexterous data. But the biggest downside of human data is the embodiment gap between robot and human. If we can reliably convert human dexterous data into robot-quality training data, then we can change the data economics of robot learning.
That is the deeper bet. It’s a better way to create the data that makes better policies possible.
A more modest view
My current view is that robotics probably will not be solved by one clean architecture choice.
World models are useful. VLAs are useful. End-to-end policies are useful. Classical planning, simulation, teleoperation, and structured industrial deployment can all be useful too.
The real question is how to combine them under today’s constraints.
For us, the most important constraints are clear: robot learning needs more high-quality data, especially for dexterous manipulation, and current robot data collection is too expensive to scale.
So our focus is simple: start from structured industrial environments, build a scalable data engine, and use human dexterity as a path toward robot dexterity.
This may not sound as grand as claiming one model paradigm will solve robotics. But it feels like a practical path forward.