
System Thinking and Model Thinking in Robot Learning
Both schools are betting on the same variable -- DATA.

Two things landed on my feed in the same week — Danfei Xu’s interview with whynotTV[1] and the latest Genesis release[2] — and the word that kept showing up in both was the same. Not a new architecture. Not a better loss. It’s the System.
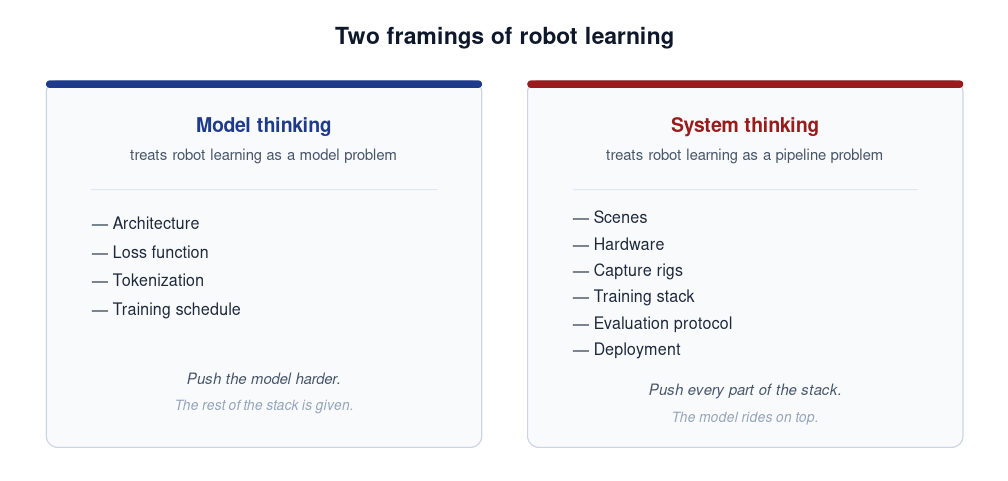
Two framings
Model thinking treats robot learning as a model problem. What matters is architecture, loss, tokenization, training schedule. Push the model harder; the rest of the stack is given.
System thinking treats robot learning as a pipeline problem. Scenes, hardware, capture rigs, training stack, evaluation, deployment — all in scope. The model is one component; push every part of the stack.
Most teams do some of both. But each team has a default — the side they invest in when they have to choose.
The model school
The cleanest commercial expression is the π-series from Physical Intelligence[3][4][5]. Each release foregrounds a model-side mechanism — fast token serialization, knowledge insulation, conditioning on mixed-quality data — with the data engine treated as a (well-invested) input rather than the research target. Real contributions; π0.7 is one of the more thoughtful pieces of model work this year.
The academic counterpart is the VLA-versus-world-model debate. World models[6] consume internet video and simulation; VLA models inherit from instruction-tuned LLMs. Both are arguments about how best to abstract robot learning into a learnable function.
In every case, the unit of innovation is the model. Data and hardware are taken as given.

The system school
The clearest example is the UMI line out of Stanford — UMI[7], HoMMI[8], DexUMI[9]. Each paper introduces a new capture rig as its load-bearing contribution; the policy network is whatever standard architecture fits the data. The point is not “a better model” — it is “a way to collect data that didn’t exist before.”
Same pattern in Danfei Xu’s ego-centric direction[1], the EgoScale / EgoVerse consortium work[10][11], and commercial programs like Generalist and Sunday.
These results seed lineages. UMI led to DexUMI, then HoMMI. EgoScale [10] led to EgoVerse [11]. Capture rigs and protocols outlive any single result. Each becomes someone else’s starting point.

The common thread
On the surface the two schools look very different. Model thinking ships architectures; system thinking ships hardware. But ask what each is actually contributing, and the answer lands in the same place.
UMI’s gripper is a way to collect manipulation data without a robot in the loop. HoMMI scales whole-body mobile capture by integrating egocentric sensing and mixed-reality interfaces. EgoScale turns egocentric video into a real training signal. Hardware is the visible artifact; data is the contribution.
Retell the model side the same way. π0.7’s mixed-quality conditioning is a method for absorbing noisier human-and-robot data without performance collapse[5]. World models use non-robot video as a denser supervision substrate. VLA absorbs internet-scale image-language pretraining into a robot policy.
The variable being optimized is data. The system school competes by enlarging the supply. The model school competes by extracting more signal per unit of existing supply. Two bets on opposite sides of the same scaling law.
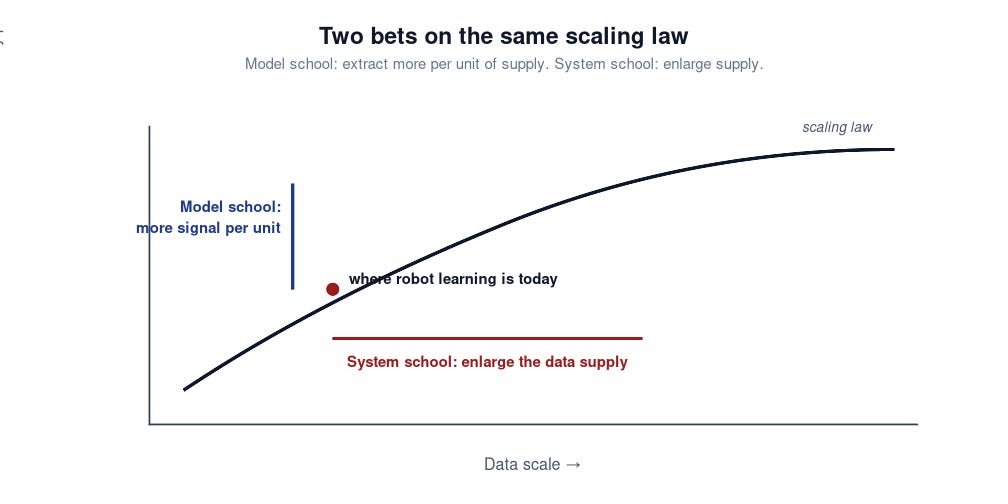
Why the system side has more room
Robot data is scarce by several orders of magnitude relative to internet-scale corpora[12]. When supply is that constrained, the biggest lever is enlarging it. Model-side innovations look smaller in absolute terms not because the work is worse — but because the supply they operate on hasn’t been allowed to grow yet.
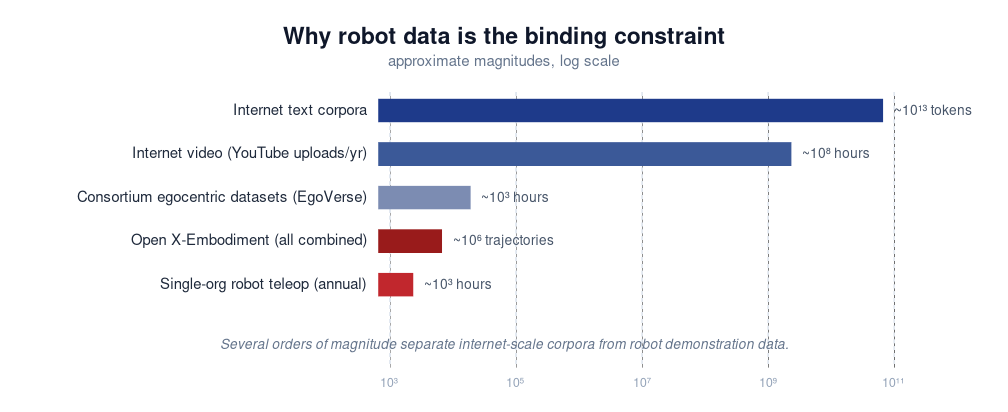
This will not last. As capture programs, consortium datasets, and simulation pipelines mature, supply expands and the relative size of the two levers shifts. CV and NLP both went through this rhythm: architecture-driven before ImageNet and Common Crawl, extraction-driven after. The honest read is not “system has won.” It is “supply is small enough right now that the side enlarging it has the larger lever.” The regime will change.
Closing
Both schools have already conceded, implicitly, that data is the binding constraint on robot learning. They disagree only about which side of the data equation to push on. For builders, the question is which side has more room right now. Right now, the room is on the system side. The teams that invest in both, and shift weight when the regime changes, are the ones I’d bet on.
References
[1] Xu, D. Interview on system-centric robot learning. whynotTV, 2026.
[2] Genesis Embodied AI. Latest release and accompanying blog post. 2026.
[3] Black, K., Brown, N., Driess, D., et al. π0: A Vision-Language-Action Flow Model for General Robot Control. Physical Intelligence, 2024. https://www.physicalintelligence.company/blog/pi0
[4] Physical Intelligence. π0.5: Knowledge Insulation for Robot Foundation Models. 2025.
[5] Physical Intelligence. π0.7: Conditioning on Mixed-Quality Robot Data. 2026.
[6] Hafner, D., et al. DreamerV3: Mastering Diverse Domains through World Models. 2023. See also LeCun, Y., A Path Towards Autonomous Machine Intelligence. 2022.
[7] Chi, C., Xu, Z., Pan, C., et al. Universal Manipulation Interface: In-the-Wild Robot Teaching Without In-the-Wild Robots. RSS 2024. https://umi-gripper.github.io/
[8] Xu, X., Park, J., Zhang, H., et al. HoMMI: Learning Whole-Body Mobile Manipulation from Human Demonstrations. arXiv:2603.03243, 2026.
[9] Stanford REAL Lab. DexUMI: Extending UMI to Dexterous Manipulation. 2025.
[10] EgoScale: Large-Scale Egocentric Pretraining for Manipulation Policies. 2025.
[11] Punamiya, Kareer, Liu, et al. EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World. 2026. https://egoverse.ai/
[12] Open X-Embodiment Collaboration. Open X-Embodiment: Robotic Learning Datasets and RT-X Models. 2024. https://robotics-transformer-x.github.io/
So true that data is important. Curious to see what data becomes the mainstream