
The right hand is the one you can capture
In embodied AI, data sourcing is the first-order question. Follow it all the way down and it rewrites the model, the morphology — and what counts as a dexterous hand.


FIG.01 — The argument in one chain — data sourcing decides the model, the morphology, and the hand.
I put on a DexUMI rig to record a few minutes of data. You move your fingers, the exoskeleton tracks them, and in theory you collect data to train a dexterous hand without ever touching a robot. Simple grasps were fine — I could pick up a cup. But the moment a task needed real dexterity, my fingers were colliding with the exoskeleton itself — the very structure meant to record them.
That’s when it clicked: the order was backwards.
For a few years now, the people coming from large language models pick the model first. The people building hardware build the hand first. The dexterous-hand teams race on degrees of freedom, payload, fingertip force. Even Elon Musk built a humanoid first. Everyone rushes to answer — and skips the real first question: where does the data come from?
Follow that one question down, and it rewrites the model, the morphology, and finally what counts as the right hand.
Training data can only come from humans
Start with the obvious: a robot has no data.
The self-driving crowd never had this problem. Millions of human-driven cars are on the road, and every brake and every lane change is data. Self-driving had a human-driving flywheel from day one. Manipulation never did.
So teleoperate, someone says — drive the robot remotely, collect data while you work, and the flywheel spins.
I’ve tried it. Teleoperating a dexterous hand is slow and shaky, the data is low quality, and the set of tasks you can do fits on one hand. Worst of all, there’s no force feedback: you have no idea what the contact feels like the moment hand meets object, which is nothing like doing it yourself. You will not assemble a base-model-scale dataset this way.
So the conclusion is blunt: training data for robots can only come from humans. Treat the human as a form of robot, capture human motion, train the model, deploy it back onto the machine. This is the deepest line between embodied AI and both self-driving and LLMs — and the starting point for every step that follows.
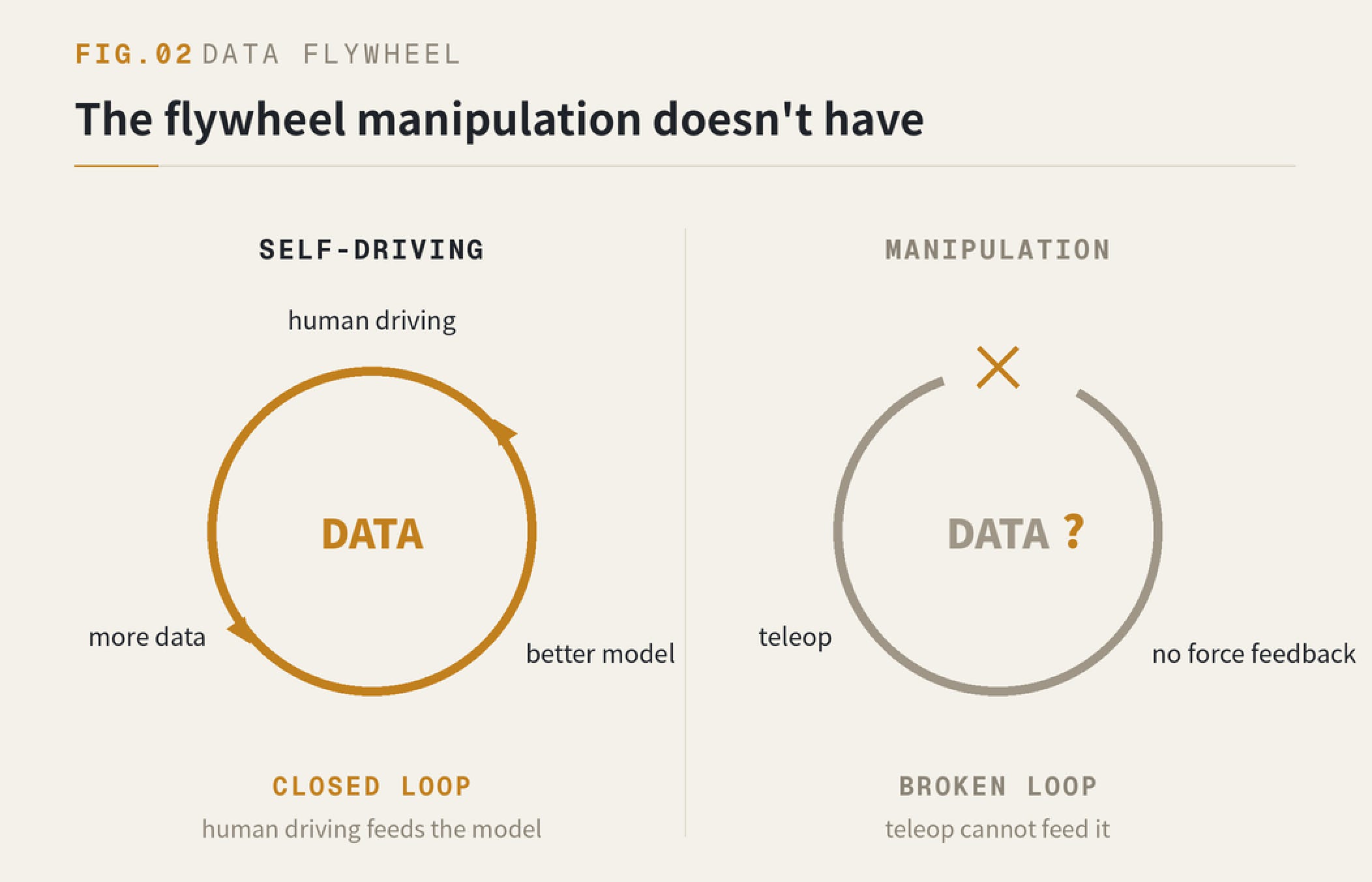
FIG.02 — The data flywheel self-driving has — and manipulation doesn’t.
The strongest signal is video, so the model feeds on video
The data source is set: first-person, egocentric — a camera on the head, recording how a human does the work. This is the data that scales most easily, and the most complete in modality.
It has one quirk: the footage is real, the actions are inferred. Reconstructing where the hand is and how it moves gets you centimeter precision at best, sometimes worse.
So what’s most valuable in this data? The video.
And there’s the answer to what the model should be. World models feed on video; VLAs feed on actions. Your strongest signal is video, so pick the architecture that learns from video — pour the most valuable part in and let it learn for all it’s worth. This isn’t picking a side between two fashionable architectures. The data forces it.
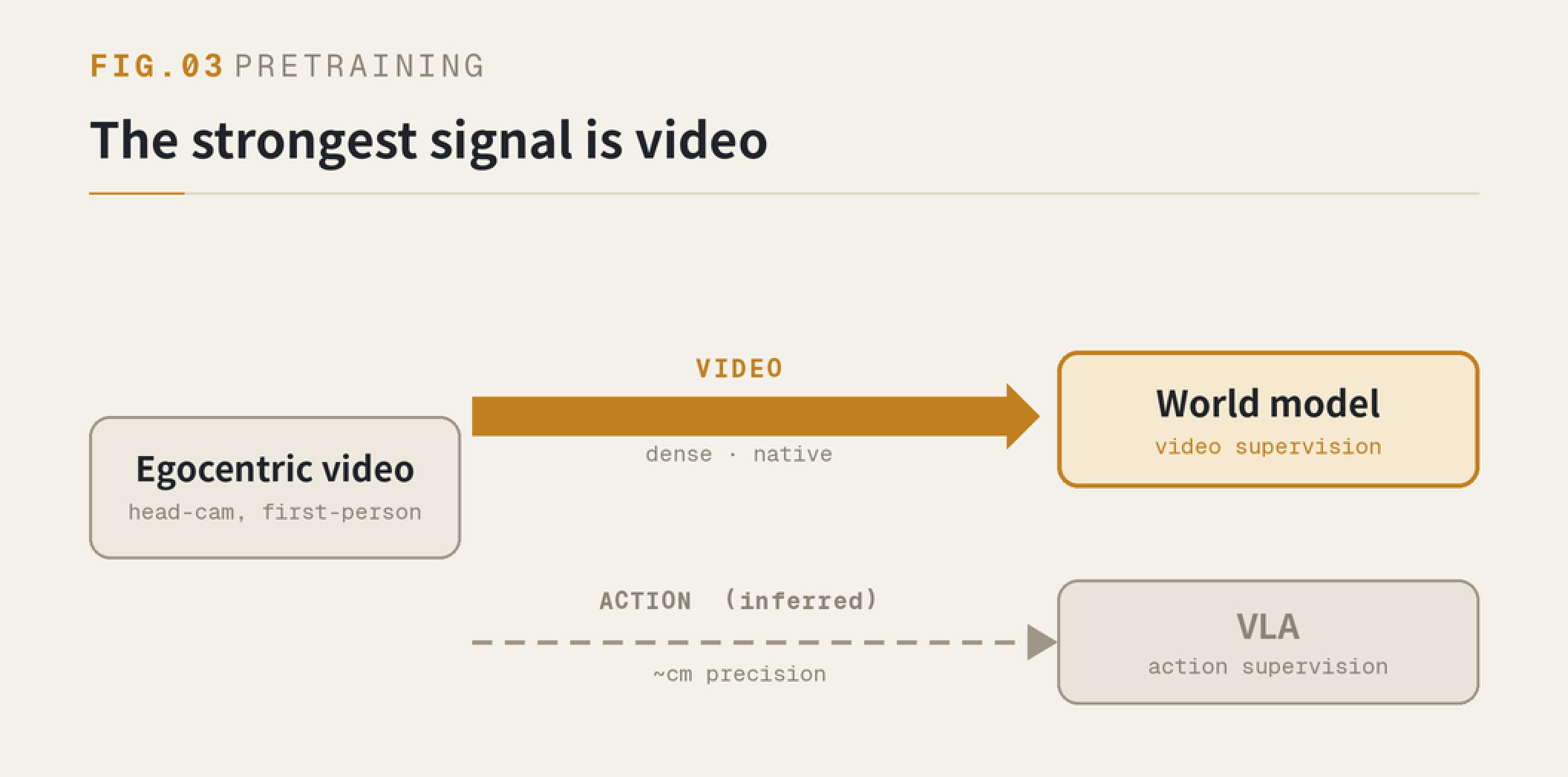
FIG.03 — Egocentric data carries a strong video signal and a weak, inferred action signal.
What post-training needs is contact precision
Pretraining feeds on video, and a world model learns a great deal from it, reliably. But a world model alone isn’t enough — eventually the model has to land on a concrete action. That’s post-training.
Use robot data, people say, teleoperated again. Back to the same problem: not enough volume, not enough quality.
What post-training is actually missing is a very specific precision — contact precision, the precision of the instant the hand meets the object. Picking up an egg, pinching a thread, twisting a cap — it’s all won or lost in that fraction of a second, that fraction of a millimeter of contact.
And that precision has a hidden killer: retargeting.
A human hand and a robot hand are different. You capture human motion, then you “translate” it onto the robot hand — that step is retargeting. The trouble is, every retargeting pass steals contact. However carefully you translate, the precision of the contact moment has already leaked out along the way.
Data gloves are the bet a lot of people place: fingertip tracking plus tactile sensors. They lose on both ends — the fingertip precision doesn’t reach a millimeter on its own, and even when it does, it still has to be retargeted onto the dexterous hand and gets shaved again.
So post-training data has one iron rule: it has to be native, with zero retargeting. Once you retarget, the precision doesn’t come back.
And there’s only one way to get to zero retargeting: capture with the robot’s own hand. That forces a dexterous-hand UMI.
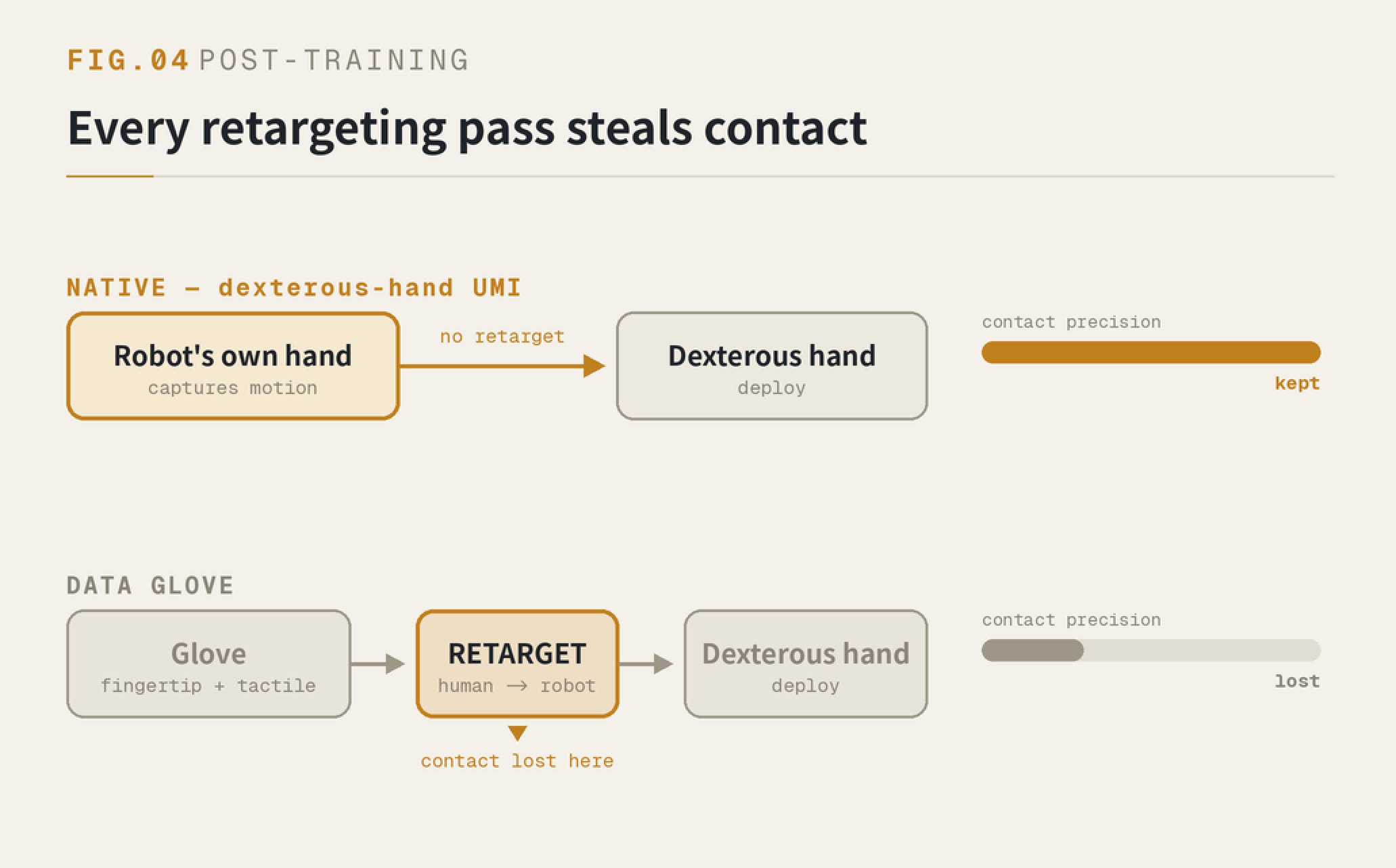
FIG.04 — Native capture keeps contact precision; the data-glove path loses it at retargeting.
“Data first” governs the brain, not the whole body
A line has to be drawn here, or two questions push back.
First: when a UMI captures, there’s no arm in the frame, and a human hand’s dynamics differ from an arm’s — so where is the “zero gap”?
The answer: UMI’s zero gap holds only at the very end — the see-something, move-the-hand loop. Inside that loop, what’s seen and what’s done are identical between capture and deployment. How the whole arm is controlled is the cerebellum’s job — a different set of rules, and unrelated to the data.
Second: does a humanoid need legs?
The same line makes it clear: “data first” governs the brain half — the hand, and the eyes watching the hand. Locomotion and legs are the cerebellum’s work, grown by simulation and RL. A humanoid doesn’t have to have legs.
Draw the boundary at the brain half, and the whole argument stands.
Capture first, then the hand
Now back to that hand of mine, fighting itself.
Hardware people share one instinct: build the dexterous hand first — more degrees of freedom, more human-like, the better — and once it’s built, go back and fit it with a capture device. The kind of work that retrofits a UMI onto an existing dexterous hand — DexUMI, for one — is exactly this.
I tried it with my own hands. On anything dexterous, my fingers fought the exoskeleton. At the time I blamed my own clumsiness. Now I see it was the order.
Start with a hand built for dexterity, then work backward for a device a human can hold and still capture clean contact through — that’s nearly impossible. The more dexterous the hand, the harder it is for a pair of human hands to reproduce in mid-air, and the dirtier the data.
The first-order thing is the capture device; the hand is derived from it. Capture first, then the hand. You decide first how a human can cleanly capture this hand’s motion, and design the hand backward from that. Dexterity yields to capturability.
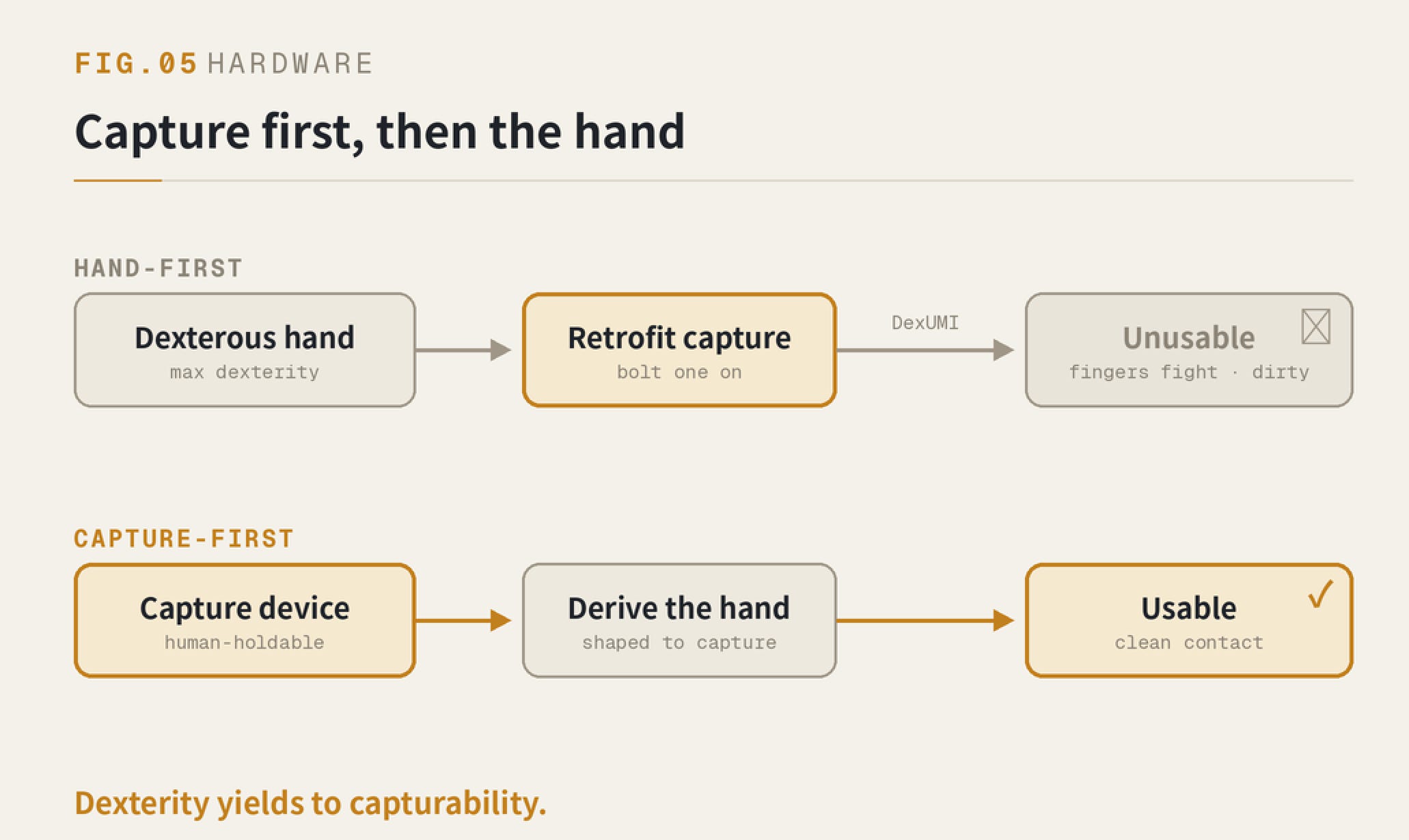
FIG.05 — Reverse the order — design the capture device first, then derive the hand from it.
Which makes the line stand on its own:
The right dexterous hand is the one that can be captured, not the most dexterous one.
Elon Musk got it half right
Chain it together: egocentric video to pretrain a world model; a dexterous-hand UMI to post-train for contact; deploy on that hand and get the work done. From the model to the hand — the subject, all the way down, is data.
Back to Elon Musk. When he lit the humanoid fire two or three years ago, I never once heard him say he was building a humanoid in order to learn from human data. He stumbled into the right answer again — only this time, half of it. The upper body and the eyes are right; the legs came along for the ride.
The hardware teams compete on fingertip force and degrees of freedom. The real contest is somewhere else:
Whose hand can be taught.